데이터 : 텍스트와 음성의 쌍이 필요하다!
# 데이터 프로세싱 : Step1. [텍스트 + 음성] 추출 / Step2. 음성을 문장별 자르기
음성합성 모델 전체 구조
텍스트를 이용하여 바로 음성으로 만드는것은 어려움으로 타코트론2는 두 단계로 나누어 수행한다.
Task1 : 텍스트 -> Mel-Spectrogram 생성 [Tacotron2]
Task2 : Mel-Spectrogram -> 음성 합성 [WaveNet]

각 과정에 따른 모델을 따로 만들고 순차적으로 따로 학습해야한다.

[Task1 - 타코트론2]
Tacotron2 이란? (텍스트[input] -> Mel-Spectogram[output])

우선 텍스트를 Encoder 에 넣기 전에 전처리과정이 필요하다.
1. Tacotron2 전처리
전처리 과정이란, ① 숫자, 특수 문자, 기호를 사전에 정해진 character로 변환하는것
② 다시 이 텍스트를 character 단위의 정수열로 변환함
그 이유는 숫자 1의 경우 상황에 따라 "일" 또는 "하나" 로 표현하기 때문에 모델의 정확도에 영향을 미치기 때문이다.

2. Tacotron2 Encoder : 텍스트(character)로 부터 특징을 추출하는 역할

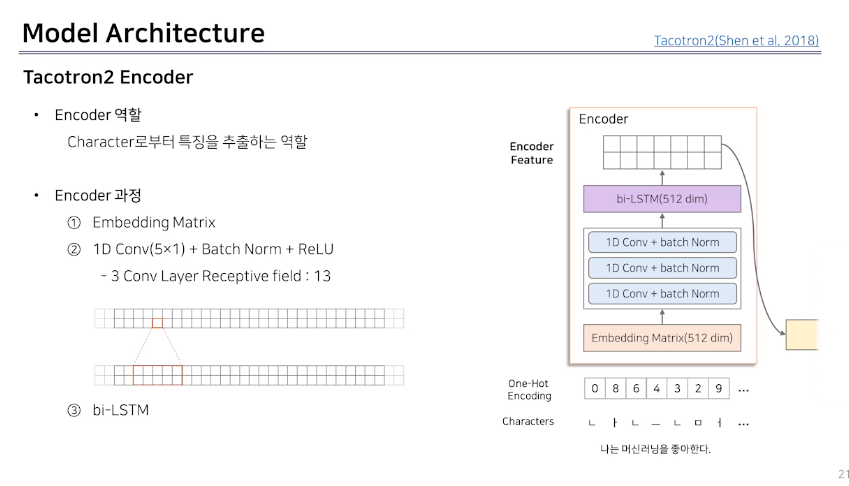
* Character Embedding 이란, 글자를 숫자로 바꿔주는 모듈(why? 딥러닝 모델이 계산을 하기위해)
ex. '띵작'을 음성합성시, 명작 + 띵동 을 Character Embedding 하여 학습이 되어있다면, 띵작을 손쉽게 음성합성 가능!!
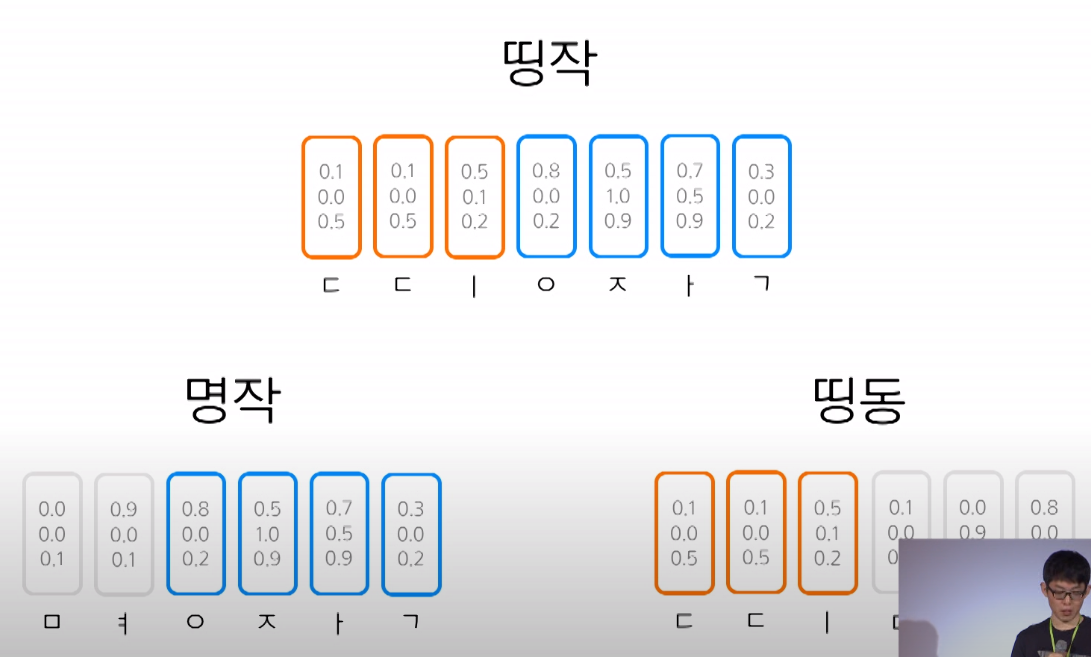
Encoder의 결과물 : 텍스트 임베딩(: 텍스트를 잘 나타내는 숫자)
3. Tacotron2 Attention : Character Embedding 과 Decoder을 잘 합쳐주는 역할
(* Attention : 어디에 집중해서 말을 해야할 것인가?)

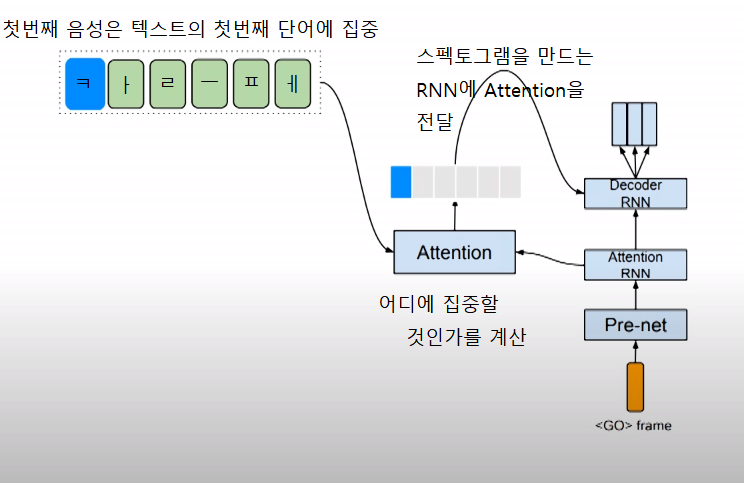
[Attention의 세부과정]
Step 1. Character Embedding (텍스트 임베딩)

Step 2. 첫번째 입력값이 들어갔을때 (Attention은 'ㄷ' 에 집중 ~> 'ㄷ' 의 Spectogram을 생성)


Step 3. 'ㅏ' 를 Attention ~> 'ㅏ' 에 대한 Spectogram 생성

Step 4. '당연히' 라는 하나의 단어를 Spectogram으로 뽑아냄

Step 5. 공백을 보고 몇 초간 쉬어줌

Step 6. 최종 결과 (우상향 그래프 형성)

※ Attention 의 학습이 중요한 이유?
일반화 때문이다.
여기서 일반화란, 학습하지 않았던 문장도 얼마나 잘 말할 수 있는가?
==> 음성합성 모델의 핵심
만약! Attention의 학습이 잘 이루어지지 않은 경우에는 아래와 같은 결과물이 발생한다.
(Decoder 부분에서 Attention이 집중하라고 하는 부분이 잘못된 것이다.)
=> 우리가 원하는 문장에 대한 음성합성 실패하게 됨.

4. Tacotron2 Decoder :
Attention 에서 얻은 정보와 이전 시점에서 생성된 멜 스펙토그램을 이용해서
멜 스펙토그램을 만든다.
( * 스팩트로그램: 음성을 숫자로 표현한것 => 스펙트로그램으로 음성을 만들 수 있다.)



1. 현재시점의 Mel-spectogram을 생성

2. 현재시점의 종료확률을 계산

3. Mel-spectogram의 품질을 향상
Decoder에서 Mel-Spectogram을 모두 생성한 다음 보정
=> 전체적인 Mel-Spectogram을 보고 Smoothing 하는 역할


=> 예측값과 실제값의 차이값을 구해서 줄이기위한 다시 학습시킨다.
[Task2 - WaveNet (Vocoder 모델)]

WaveNet : Mel-Spectogram을 조건으로 음성을 생성하는 모델.


WaveNet은 확률론적 모델링을 통해 역할 수행
=> 과거 시점까지 음성 데이터를 조건으로 현재 시점에서 특정 음성이 등장할 확률을 추출
=> 이렇게 학습된 WaveNet을 계속 반복적으로 수행하면 새로운 음성을 합성할 수 있다.

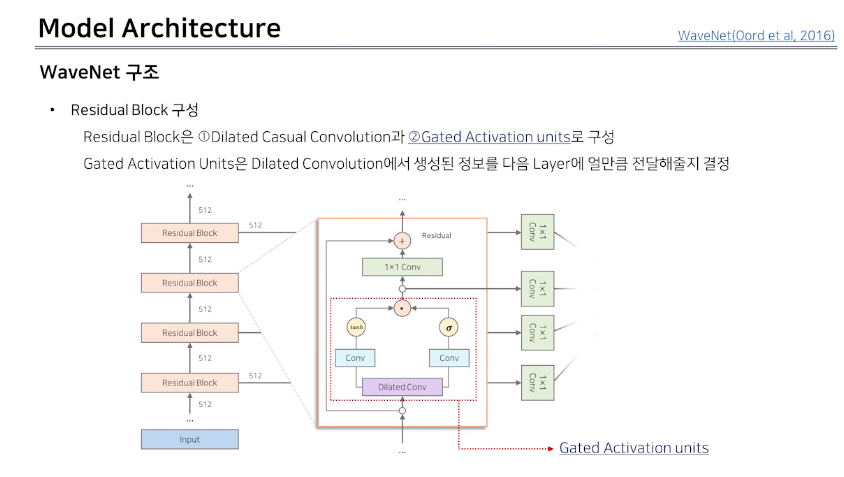
WaveNet은 30개의 Residual Block으로 구성되어있다.
각 Residual Block에서 추출된 결과물 출력되는 Skip Connection을 통해서 합쳐준다.
* Residual Block이란?
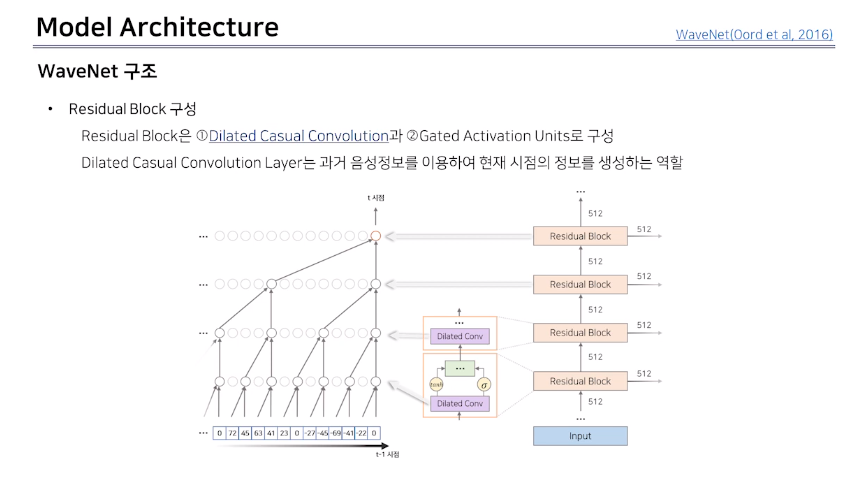
1. Dilated Casual Convolution 과 2. Gated Activation Units 로 구성한다.
1. Dilated Casual Convolution

2. Gated Activation Units


이번에는 WaveNet에 조건을 추가하여 사용자의 의도가 들어간 음성을 생성할 수 있도록 변환한 구조
사용자의 의도의 맞게 현재 음성분포를 추론할 수 있도록 모델을 수정하기 위해서는 몇가지 구조를 추가해야한다.
아래 그림은 사용자가 정의 특징을 삽입할 수 있는 구조가 추가된 Conditional WaveNet이다.
사용자가 정의한 특징은 음성 전체에 영향을 미치는 전역적 특징이 될 수 있다.
혹은 특정 시점에만 영향을 미치는 지역적 특징을 WaveNet에 추가할 수 있다.

1. 전역적 특징을 Conditional WaveNet 적용하는 방법

전역적 특징의 구체적인 예시는 화자의 속성이다.
여러명의 화자를 구분하여 음성을 생성하고 싶은 경우에 전역적 특징으로 화자의 정보를 조건으로 사용한다.
적용방법은 각 화자의 관련된 임베딩 메트리스를 만들고 이를 입력으로 활용한다.
Convolution Set을 통과하여 가공된 임베딩 메트리스는 각 Residual Block의 Gated Activation Units에 또 다른 변수로 적용된다. 이 조건은 음성의 모든 시점에 일관적으로 동일하게 적용됨으로 전역적 조건으로써 음성생성에 영향을 준다.
2. 지역적 특징을 Conditional WaveNet 적용하는 방법

지역적 특징에 구체적인 예시는 Mel-spectogram이다.
즉, 특정 음성에 해당하는 멜 스펙토그램을 조건으로 사용하면 특정 음성과 비슷한 음성을 생성하도록 조정할 수 있다.
다만 지역적 특징을 부여하기 위해서는 음성과 길이가 같은 벡터를 조건으로 넣어야한다.
하지만 일반적으로 멜 스펙토그램이나 다른 지역적 특징 벡터들은 음성과 길이가 같지 않은 벡터이다.
따라서 조건 벡터와 음성 길이를 일치시켜야한다.

위와 같이 길이를 조절 할 수 있는 멜 스펙토그램은 음성 생성 시점에 따라 다르게 적용됨으로 지역적 조건으로 작동한다.

각 Residual Block 으로 부터 생성된 결과는 Skip Connection 을 통해 하나의 벡터로 만들어진다.
몇개의 Convolution Layer 를 통해 가공된 후 음성 파형 확률을 도출한다.
일반적으로 아래 빨간색으로 표시된 부분처럼 Softmax 를 통해 카테고리 분포를 만들고 학습한다.
하지만 이러한 구조는 비슷한 값을 갖고있는 음성파형값은 비슷한 의미를 지닌다는 음성의 특징을 반영하지 못한다.
따라서 주변의 관계를 고려한 확률분포 생성 방법이 필요하다.

여러개의 로지스틱 분포를 합쳐 카테고리 분포를 만드는 것.
이 방법을 활용하면 서로 가까이에 있는 카테고리 값은 비슷한 확률을 가질 가능성이 높다.
따라서 주변 관계를 고려한 확률 분포를 생성할 수 있다.
이를 적용하기 위하여 WaveNet의 결과물로 각 로지스틱 분포에 파라미터 추정값을 도출한다.
그 다음 도출된 파라미터로 로지스틱 함수를 만들고 합쳐 PDF를 만들면 전체 PDF를 생성 할 수 있다.
특정 카테고리의 확률을 구하는 것은 특정 카테고리에 속하는 경계면까지의 누적 확률을 구하면 된다.
ex. 4가 나올 확률은 3.5 ~ 4.5 까지의 누적확률을 계산하여 도출할 수 있다.

참고: https://www.youtube.com/watch?v=BmD8OA9FGR0
'음성합성' 카테고리의 다른 글
| 음성 합성 #001 (0) | 2021.05.20 |
|---|
